Regression_Step 01_02¶
Abstract¶
Machine learning applications have evolved in the fields of ranging from Natural Language Processing to the vast majority of business functions, one of which is taking place in a real estate field. While machine learning does not take over the real estate professinoals tasks, it will help people perform complicated task especially realted to a realtively large amount of data.
Objectives¶
This project focuses on quantitative data science and mainly aims to perform two goals. One is to predict housing price based on multiple variables such as room size or building types etc. The other is to forecast sales of a real estate company.
Regression_Step 02 Data Wrangling¶
Source of a data set¶
Source: Kaggle page https://www.kaggle.com/ruiqurm/lianjia
This includes URL, ID, Lng, Lat, CommunityID (Cid), TradeTime, DOM(days on market), Followers, Total price, Price, Square, Living Room, number of Drawing room, Kitchen and Bathroom, Building Type, Construction time. renovation condition, building structure, Ladder ratio( which is the proportion between number of residents on the same floor and number of elevator of ladder. It describes how many ladders a resident have on average), elevator, Property rights for five years(It's related to China restricted purchase of houses policy), Subway, District, Community average price.
All the data was coming from https://bj.lianjia.com/chengjiao.
'price' in this data seems what is known as unit price, which should equal to totalPrice/square.
(buildingType == 1 ~ "Tower", buildingType == 2 ~ "Bungalow", buildingType == 3 ~ "Plate/Tower", buildingType == 4 ~ "Plate")
(renovationCondition == 1 ~ "Other", renovationCondition == 2 ~ "Rough", renovationCondition == 3 ~ "Simplicity", renovationCondition == 4 ~ "Hardcover")
(buildingStructure == 1 ~ "Unavailable", buildingStructure == 2 ~ "Mixed", buildingStructure == 3 ~ "Brick/Wood", buildingStructure == 4 ~ "Brick/Concrete", buildingStructure == 5 ~ "Steel", buildingStructure == 6 ~ "Steel/Concrete")
(elevator == 1 ~ "Has_Elevator", elevator != 1 ~ "No_elevator"))
(subway == 1 ~ "Has_Subway", subway != 1 ~ "No_Subway")
(fiveYearsProperty == 1 ~ "Ownership < 5y", fiveYearsProperty != 1 ~ "Ownership > 5y")
(district == 1 ~ "DongCheng", district == 2 ~ "FengTai", district == 3 ~ "DaXing", district == 4 ~ "FaXing", district == 5 ~ "FangShang", district == 6 ~ "ChangPing", district == 7 ~ "ChaoYang", district == 8 ~ "HaiDian", district == 9 ~ "ShiJingShan", district == 10 ~ "XiCheng", district == 11 ~ "TongZhou", district == 12 ~ "ShunYi", district == 13 ~ "MenTouGou"))
Introduction¶
This notebook is data wrangling part of a self projects of Housing price in Beijing.
Imports¶
For data import, cleaning, and visualization, import pandas, numpy, scipy, random and matplotlib.pyplot
For machine learning from sklearn, import LinearRegression
import warnings
warnings.filterwarnings('ignore')
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
from IPython.display import clear_output
import os
from library.sb_utils import save_file
Other libraries and fnuciton will be imported as necessary.
Configuration¶
pd.set_option('display.max_columns', 100)
pd.set_option('display.max_rows', 100)
pd.options.display.float_format = '{:.4f}'.format
Objective¶
The goals of this project are followings.
- Goal 1: Prediction model for housing price
- Goal 2: Forecast model for sales
In this notebook, we wrangle data and make data ready for EDA, which will be the next step.
Load Data¶
The csv file of the raw data has already been downloaded from the Kaggle website. The file is located in the folder named raw_data.
They include a column of datetime type, 'tradeTime'(yyyy-mm-dd). This will be converted to datatime type. As for the encoding, we go on with the 'iso-8859-1'.
Here, we download the file with the specification mentoined above as df. Not only this, but we also keep original dataframe in order to make it easier to check and compare, which is named as original_df.
df = pd.read_csv('../raw_data/Housing price in Beijing.csv',encoding='iso-8859-1',parse_dates = ['tradeTime'])
original_df = df.copy()
df.sort_values('tradeTime',inplace=True)
This warning says there are some mixed data types in the columns and we will be aware of this when cleaning.
Explore The Data for cleaning¶
Display general information with info method to check #rows, column names, Null value, Dtype.
df.info()
The missing values are found in some columns, 6,16,11-23,25. These will be fixed later.
df.describe().T
Check the first 5 rows to visually check the data itself.
df.head()
All the data seem ok except the floor column, which seems to have two types of information, forward part and aftward part. The forward part of the floor data column is unreadable for some reasons, but we can still use one as categorise. The aftward part of the floor data column looks perfect.
Data Cleaning¶
Overview¶
Based on the df.info(), some problems have been found. In this section, we will deal with the error one by one.
In order to make comaprison easier, extract year and month in differect columns respectively.
df['year'] = df.tradeTime.apply(lambda x: x.year)
df['month'] = df.tradeTime.apply(lambda x: x.month)
df.sort_values('tradeTime',inplace=True)
'bathRoom' column: Comapare correct and wrong data¶
First error found is the data in the wrong columns. For example, the bathroom has some unreasonable data set.
df.bathRoom.unique()
Now we explore what wrong is going in 'bathRoom' column. As we can see, 'bathRoom' column has 2006, 2003 etc which seem to be year. However, these 2003 and 2006 are supposed to be seen only in constructionTime column.
To see the details, we now compare correct data using sample of (bathRoom == 6 or 7) and the wrong data (bathRoom == 1990)
df[(df['bathRoom']==1990)|(df['bathRoom']==6)|(df['bathRoom']==7)].head(4)
We also found that the rows that have wrong data in bathrom also include another wrong data, #NAME? in livingRoom column.
Now we check the rows with #NAME? in livingRoom columns.
df[df.livingRoom=='#NAME?'].head()
len(df[df.livingRoom=='#NAME?'])
Based on this result, we found that 32 rows of livingRoom=='#NAME?' data, and also found that not only bathRoom but also the other columns upto ladderRatio column also have wrong data that should have been in a column by 3 to the right. Based on this observation, one solution to this problems will be following. regarding the rows with 'year' or any objects other than the integers less than 100 in 'bathRoom' column (as there will be no house with 100 bathrooms), it may be an option to shift these wrong data, horizontally by 3 columns to the right. The columns to shift are from livingRoom to ladderRatio.
Another problem found is that the original data in the buildingType seems actually the data that should have been ladderRatio, which is FOUR columns to the right.
Although there may be some solution to save these 32 rows of data, it will be difficult to presume which column is right location to shift the wrong data to. In addition, the 32 rows of data are relatively quite small compared to entire rows of 318850. Furthermore, it will be difficult to predict the missing values which will be created by shifting to salvge 32 rows. Our conclusion is to drop the 32 rows that have livingRoom=='#NAME?'.
df = df[df.livingRoom!='#NAME?']
Separate Categorical feature ¶
Original 'floortype' column has two categorical features in the columns Separate them into two of new columns.
df['floor'].unique()
def floorType(s):
try:
return s.split(' ')[0]
except:
return np.nan
def floorHeight(s):
try:
return int(s.split(' ')[1])
except:
return np.nan
df['floorType'] = df['floor'].map(floorType)
df['floorHeight'] = df['floor'].map(floorHeight)
df.head()
Confirmed floorType and floorHeight have been created and each has categorical values and numerical values, respectively.
df.drop('floor',axis=1,inplace=True)
Data type in bathRoom¶
df.bathRoom.unique()
Columns of 11,12,14,15,16 have object type data and seem to have mixed datatype. We will convert them to int type.
df.iloc[:,[11,12,14]] = df.iloc[:,[11,12,14]].applymap(int)
# Confirm the result
df.bathRoom.unique()
Data type in floorType¶
# Check the current categorical values in floorType
df.floorType.unique()
from sklearn.preprocessing import LabelEncoder
le = LabelEncoder()
df.floorType = le.fit_transform(df.floorType)
# Confirm the new categorical values
df.floorType.unique()
Data type in constructionTime¶
'constructionTime''s datatype should be year or time.
df.constructionTime.unique()
len(df[df.constructionTime=='δ֪']),df[df.constructionTime=='δ֪']['tradeTime'].apply(lambda x: x.year).unique()
One unreadable str,'δ֪', has been found, which counted 19283. Those row have relatively new years.
Our hypothesis is that this 'δ֪' means new house.
Now we check the data which do not have 'δ֪' to compare construction year and tradeTime year.
constIsLater = df[df.constructionTime!='δ֪'].constructionTime.astype(int) > df[df.constructionTime!='δ֪']['tradeTime'].apply(lambda x: x.year)
constIsSame = df[df.constructionTime!='δ֪'].constructionTime.astype(int) == df[df.constructionTime!='δ֪']['tradeTime'].apply(lambda x: x.year)
constIsEarlier = df[df.constructionTime!='δ֪'].constructionTime.astype(int) < df[df.constructionTime!='δ֪']['tradeTime'].apply(lambda x: x.year)
print(sum(constIsLater),
sum(constIsSame),
sum(constIsEarlier)
)
Base on this comparison, we conclude our hyputhesis is resonable.
Now we replace 'δ֪' for the tradeTime year.
def _const_correction(cols):
construction_year = cols[0]
if construction_year=='δ֪':
return int(cols[1])
else:
return int(cols[0])
df['constructionTime']= df[['constructionTime','year']].apply(_const_correction,axis=1)
Final check for data type¶
df.info()
Null values¶
Major possible options are as follows.
- Drop off the rows with Null
- Imute a Null call(missing value) for a value
- Drop off the columns with Null
Visualise and scale the NaN values
import missingno as msno
import matplotlib.pyplot as plt
print(df.isnull().sum()/len(df)*100)
# sns.heatmap(df.isnull(),yticklabels=False,cbar=False,cmap='viridis')
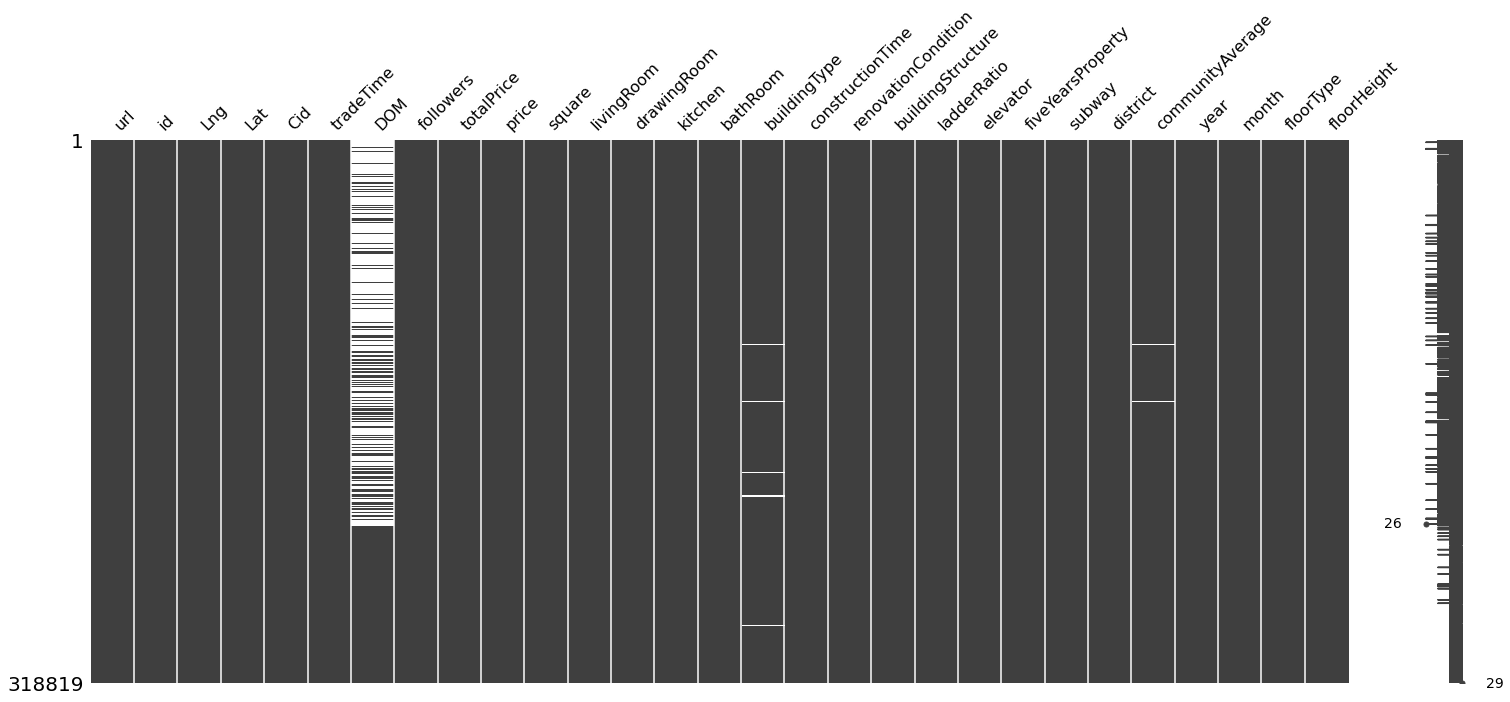
# Visualize missingness
msno.matrix(df)
plt.show()
df.isna().sum().plot(kind="bar") plt.show()
Based on this information, there are three columns which have null data, among which the missing percentage of data in DOM column is significantly large, 49.55%. In the following sections, impute these missing data column by column.
Null in 'new_buildingStructure'¶ ¶
Replace the null data in this column for valid data.
df['buildingType'].isnull().sum()
2021 is quite a lot.
df['buildingType'].unique()
Instead of dropping them, careate and put a new category label, 5.
df['buildingType'] = df['buildingType'].replace({np.nan:5})
df['buildingType'].unique()
df.isnull().sum()/len(df)*100
Null in 'communityAverage'¶
Before imputing community average, check how community average has been calculated.
# Make a list of columns that seem related to community average.
checklist = ['communityAverage','Cid','totalPrice','price','year','month','district','buildingType','buildingStructure']
# Make a new dataframe of checklist
comAveSet = df[checklist]
# Check the max of communityAverage
comAveSet.communityAverage.max()
# Find the constant value to search the which values are used to make a average of communityAverage
comAveSetmax = comAveSet[comAveSet.communityAverage==comAveSet.communityAverage.max()]
pd.set_option('display.float_format', lambda x: '%.2f' % x)
comAveSetmax.describe().T
# Another search
comAveSetsecmax = comAveSet[comAveSet.communityAverage==146634.0]
pd.set_option('display.float_format', lambda x: '%.2f' % x)
comAveSetsecmax.describe().T
From these analysis, community average seems the average price in a district or Cid. More importantly, community average is the value averaged over multiple years.
Firstly check # of unique data in each column.
len(df['Cid'].unique()),len(df['communityAverage'].unique()),len(df['district'].unique())
Next, check the summary for single Cid (117800835289894).
df[df.Cid==117800835289894].describe().T
The communityAverage has 4073 unique numbers, while Cid has 4035. They are very close. #Cid and #communityAverage are almost same, but district is too small comapred to 4073, #communityAverage.
In a single district, there are so many Cid. Also, although I have deleted the map analysis as the data is hundreds MB heavy, from geographical relathion between Cid and district, the broundary between district is not clearly identical as Cid boundary, which means that on the boundary of district, there are several Cid are mixed.
We conclude followings.
- It is less likely the community average is average of a district and
- Cid seems the most strongly related to communityAverage.
- CommunityAverage is average values regardless years
In order to keep feature variables independent and meaningful, drop communityAverage column.
df.drop('communityAverage',inplace=True,axis=1)
# confirm the remaining null.
df.isnull().sum()/len(df)*100
Null in 'DOM'¶
The definition of DOM is the days on market. If the day on market are longer than other houses, customers looking for houses start to suspect there are promblems with the houses.
msno.matrix(df)
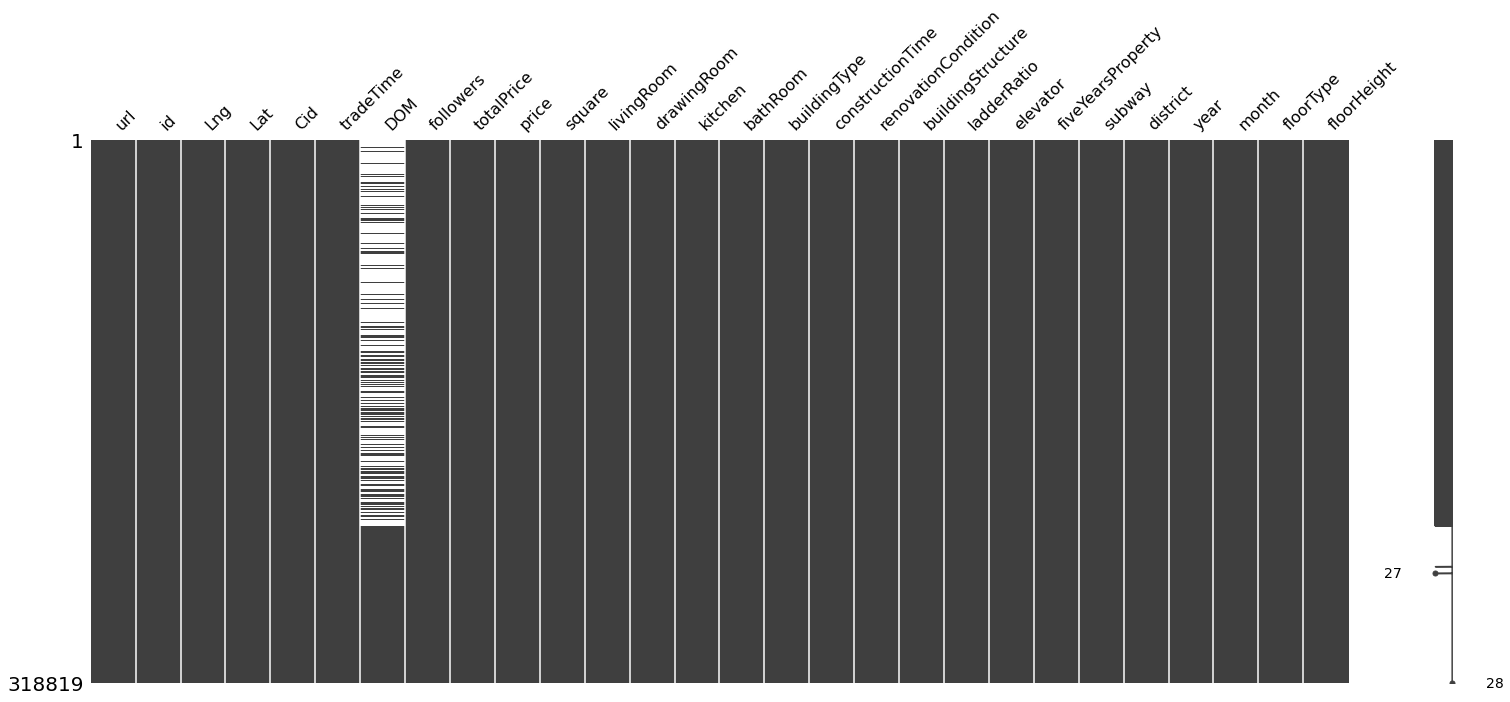
The vast majority of missing values are ealier time of this data set.
df.describe().DOM
DOM seems important value, so somehow we are willing to impute the missing.
Because of much discrepancy among median, mean, and maximum value, we will further analysis, which will happen in next EDA. So, for now, we will keep this missing values in DOM column.
# df['DOM'] = df['DOM'].fillna(1.0)
# Final check
df.isnull().sum()/len(df)*100
Save data¶
This should be done aftre imputation of communityAverage as there are null values in the column.
# save the data to a new csv file
datapath = '../data'
save_file(df, 'data_step2_cleaned.csv', datapath)
Summary¶
The key processes and findings from this notebook are as follows.
- Original rows in the data: 318851 rows
- Rows deleted: 32 rows These data included 10 columns misplaced and 6 missing feature values.
- Rows after cleaning: 318819 rows
The removed columnns
- communityAverage: This column had average value over several years and had strong relationship with Cid and seems dependent on Cid and price or totalPrice. Based on our objectives in sec4, one of our goals is to analyze time series change in price. Therefore, this average price will not be necessary and has been deleted.
DOM column Although there are large amount of missing values in DOM columns, as this DOM is considered to be one of important Key Performance Indicator in real estate, we will leave out the imputation for DOM in this datawrangling and further explore in 03 EDA notebook.
Price and totalPrice As discussed above, there is suplicaiton in price information. For example, 'totalPrice' seems equal to 'price' multiplied by 'square'. Either of the columns will need to be removed, but we will discuss about this in EDA.