Step 02 Data Wrangling¶
Introduction¶
In the previous step 01 Problem statement, we have defined the goal of this project and just have downloaded hte raw data.
In this step 02 Data Wrangling, we clean up the data as much as we can to make it ready for the next step EDA(Exploratory Data Analysis).
The major tasks will be to check the data type used, missing values, and transform the style as necessary.
Imports¶
import warnings
warnings.filterwarnings('ignore')
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
from IPython.display import clear_output
import os
from library.sb_utils import save_file
Load data¶
dfm = pd.read_csv('../data/step1_dfm.csv')
dfr = pd.read_csv('../data/step1_dfr.csv',parse_dates = ['reviewTime'])
# convert dataframe values to string
dfm = dfm.astype(str)
# remove the html tags
# http://www.compjour.org/warmups/govt-text-releases/intro-to-bs4-lxml-parsing-wh-press-briefings/
def remove_html_tags(raw_html):
from bs4 import BeautifulSoup
cleantext = BeautifulSoup(raw_html, "lxml").text
return cleantext
check duplicates¶
# Regarding meta data, check for duplicates
dfm.duplicated().sum(),dfr.duplicated().sum()
check null¶
# Any null entries
dfm.isnull().values.any(),dfm.isnull().values.any()
There seems to be no missing data, but the current missing values are filled with empty, which saves time in the following process. So, we go ahead as they are now.
meta data¶
dfm.info()
category column¶
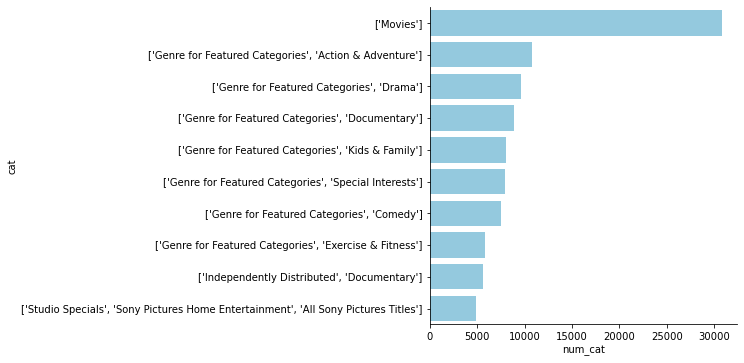
dfm.category.value_counts().to_frame()
It is found that the data in category has some levels although the first level, 'Movies & TV', will not be necessary
# check what is in 'Special Interests' category
dfm[dfm.category.str.contains('Special Interests')].category.unique()
I thought that the parents of 'Special Interests' is identical, but they are different and there is no consistency to avoid duplicated naming in the category structure.
# Convert the list-like string to list
from ast import literal_eval
dfm.category = dfm.category.apply(lambda x: literal_eval(x))
max_cat = dfm.category.apply(len).max()
max_cat
The maxium #level of categories is 7.
dfr.overall.value_counts(dropna=False)
dfr[dfr.overall=='']
# for i in range(max_cat):
# dfm[str('cat'+str(i+1))] = dfm['category'].apply(lambda x: x[i] if i<len(x) else '')
# remove 'Movies & TV' as this meta and review dataframe is only ordinally from 'Movies & TV' category, and it is unnecessary
dfm['category'].apply(lambda x : x.remove("Movies & TV") if "Movies & TV" in x else x)
# print the unique values and its count
categories = dfm.category.value_counts().to_frame()
categories = categories.reset_index()
categories.columns = ['cat','num_cat']
categories.cat = categories.cat.apply(str)
# Number of movies per category
sns.catplot(data = categories.iloc[:10], x = 'num_cat', y = 'cat', kind = 'bar', orient= 'h', color="skyblue");
# stock = []
# for i in range(len(categories)):
# stock.append(dfm.iloc[i].category[0])
# set(stock)
main_cat¶
dfm.main_cat.value_counts().to_frame()
dfm[dfm['main_cat']!='Movies & TV'].head()
They are unnecessary.
dfm = dfm[dfm['main_cat']=='Movies & TV']
description column¶
# Check the description
dfm.description.value_counts().to_frame().tail(2)
# check the data in the row of 66812.
dfm.iloc[66812].description
Clean in the same way as above
# Fill empty categories with empty string
dfm['description'] = dfm['description'].apply(lambda x: '' if x == '[]' else x)
# Clean html letter code
dfm['description'] = dfm[['description']].applymap(remove_html_tags)
# confirm the result
dfm.iloc[66812].description
# check other rows
dfm[dfm.description.str.contains('///')].iloc[3].description
We still have unnecessary characters such as the \\ or /// but now just leave them.
?? remove the \\ or ///
title column¶
dfm.title.value_counts().to_frame()
# Clean html letter code
dfm['title'] = dfm[['title']].applymap(remove_html_tags)
# remove any leading and trailing spaces
dfm['title'] = dfm[['title']].apply(lambda x: x.str.strip() if x.dtype == "object" else x)
# replace nan for ''
dfm['title'] = dfm[['title']].replace('nan', 'no-title')
dfm.title.value_counts().to_frame()
brand column¶
dfm.brand.value_counts().to_frame()
# Clean html letter code
dfm['brand'] = dfm[['brand']].applymap(remove_html_tags)
# remove any leading and trailing spaces
dfm['brand'] = dfm[['brand']].apply(lambda x: x.str.strip() if x.dtype == "object" else x)
# replace specific values for ''
dfm['brand'] = dfm[['brand']].replace(['nan','.','-','*','','None'], 'no-brand')
dfm.brand.value_counts().to_frame()
asin¶
print('The number of products: {}'.format(dfm.asin.nunique()))
review data¶
dfr.info()
overall¶
dfr[['overall','reviewTime']].describe().T
reviewerID¶
print('The number of reviewer in review data: {}'.format(dfr.reviewerID.nunique()))
asis¶
print('The number of products in review data: {}'.format(dfr.asin.nunique()))
Delete unnecessary data¶
# Delete the rows that only exist in the either review or meta data
dfm = dfm.astype(str).drop_duplicates()
dfr = dfr.astype(str).drop_duplicates()
Save data¶
This should be done aftre imputation of communityAverage as there are null values in the column.
# save the data to a new csv file
datapath = '../data'
save_file(dfm, 'step2_cleaned_dfm.csv', datapath)
save_file(dfr, 'step2_cleaned_dfr.csv', datapath)
Summary¶
The key processes and findings from this notebook are as follows.
- Rows deleted: The rows(asin in the meta data) have been deleted.
- Columnns deleted: 0 column
- meta data
- Category column: Some data which seem unnecessary such as 'Movies or TV' have been removed (possibly they could have been splited into separate columns of 'Movies or TV' and 'Featured genre') It was expected to visualise the structure of category usig node to clarify the structure, but it takes time and not the main purpose here, so category data was remained as it is.
- Description column: html script has been removed, but some symbols such as '\\' or '///' still remains. Those unnecessary symbols will be removed as necessary in the future steps.