Springboard Data Science Career Track Unit 4 Challenge - Tier 3 Complete¶
Objectives¶
Hey! Great job getting through those challenging DataCamp courses. You're learning a lot in a short span of time.
In this notebook, you're going to apply the skills you've been learning, bridging the gap between the controlled environment of DataCamp and the slightly messier work that data scientists do with actual datasets!
Here’s the mystery we’re going to solve: which boroughs of London have seen the greatest increase in housing prices, on average, over the last two decades?
A borough is just a fancy word for district. You may be familiar with the five boroughs of New York… well, there are 32 boroughs within Greater London (here's some info for the curious). Some of them are more desirable areas to live in, and the data will reflect that with a greater rise in housing prices.
This is the Tier 3 notebook, which means it's not filled in at all: we'll just give you the skeleton of a project, the brief and the data. It's up to you to play around with it and see what you can find out! Good luck! If you struggle, feel free to look at easier tiers for help; but try to dip in and out of them, as the more independent work you do, the better it is for your learning!
This challenge will make use of only what you learned in the following DataCamp courses:
- Prework courses (Introduction to Python for Data Science, Intermediate Python for Data Science)
- Data Types for Data Science
- Python Data Science Toolbox (Part One)
- pandas Foundations
- Manipulating DataFrames with pandas
- Merging DataFrames with pandas
Of the tools, techniques and concepts in the above DataCamp courses, this challenge should require the application of the following:
- pandas
- data ingestion and inspection (pandas Foundations, Module One)
- exploratory data analysis (pandas Foundations, Module Two)
- tidying and cleaning (Manipulating DataFrames with pandas, Module Three)
- transforming DataFrames (Manipulating DataFrames with pandas, Module One)
- subsetting DataFrames with lists (Manipulating DataFrames with pandas, Module One)
- filtering DataFrames (Manipulating DataFrames with pandas, Module One)
- grouping data (Manipulating DataFrames with pandas, Module Four)
- melting data (Manipulating DataFrames with pandas, Module Three)
- advanced indexing (Manipulating DataFrames with pandas, Module Four)
- matplotlib (Intermediate Python for Data Science, Module One)
- fundamental data types (Data Types for Data Science, Module One)
- dictionaries (Intermediate Python for Data Science, Module Two)
- handling dates and times (Data Types for Data Science, Module Four)
- function definition (Python Data Science Toolbox - Part One, Module One)
- default arguments, variable length, and scope (Python Data Science Toolbox - Part One, Module Two)
- lambda functions and error handling (Python Data Science Toolbox - Part One, Module Four)
The Data Science Pipeline¶
This is Tier Three, so we'll get you started. But after that, it's all in your hands! When you feel done with your investigations, look back over what you've accomplished, and prepare a quick presentation of your findings for the next mentor meeting.
Data Science is magical. In this case study, you'll get to apply some complex machine learning algorithms. But as David Spiegelhalter reminds us, there is no substitute for simply taking a really, really good look at the data. Sometimes, this is all we need to answer our question.
Data Science projects generally adhere to the four stages of Data Science Pipeline:
- Sourcing and loading
- Cleaning, transforming, and visualizing
- Modeling
- Evaluating and concluding
1. Sourcing and Loading¶
Any Data Science project kicks off by importing pandas. The documentation of this wonderful library can be found here. As you've seen, pandas is conveniently connected to the Numpy and Matplotlib libraries.
Hint: This part of the data science pipeline will test those skills you acquired in the pandas Foundations course, Module One.
1.1. Importing Libraries¶
# Let's import the pandas, numpy libraries as pd, and np respectively.
import pandas as pd
import numpy as np
# Load the pyplot collection of functions from matplotlib, as plt
import matplotlib.pyplot as plt
1.2. Loading the data¶
Your data comes from the London Datastore: a free, open-source data-sharing portal for London-oriented datasets.
# First, make a variable called url_LondonHousePrices, and assign it the following link, enclosed in quotation-marks as a string:
# https://data.london.gov.uk/download/uk-house-price-index/70ac0766-8902-4eb5-aab5-01951aaed773/UK%20House%20price%20index.xls
url_LondonHousePrices = "https://data.london.gov.uk/download/uk-house-price-index/70ac0766-8902-4eb5-aab5-01951aaed773/UK_House_price_index.xlsx"
# The dataset we're interested in contains the Average prices of the houses, and is actually on a particular sheet of the Excel file.
# As a result, we need to specify the sheet name in the read_excel() method.
# Put this data into a variable called properties.
properties = pd.read_excel(url_LondonHousePrices, sheet_name='Average price', index_col= None)
2. Cleaning, transforming, and visualizing¶
This second stage is arguably the most important part of any Data Science project. The first thing to do is take a proper look at the data. Cleaning forms the majority of this stage, and can be done both before or after Transformation.
The end goal of data cleaning is to have tidy data. When data is tidy:
- Each variable has a column.
- Each observation forms a row.
Keep the end goal in mind as you move through this process, every step will take you closer.
Hint: This part of the data science pipeline should test those skills you acquired in:
- Intermediate Python for data science, all modules.
- pandas Foundations, all modules.
- Manipulating DataFrames with pandas, all modules.
- Data Types for Data Science, Module Four.
- Python Data Science Toolbox - Part One, all modules
2.1. Exploring your data
Think about your pandas functions for checking out a dataframe.
properties.head()
2.2. Cleaning the data
You might find you need to transpose your dataframe, check out what its row indexes are, and reset the index. You also might find you need to assign the values of the first row to your column headings . (Hint: recall the .columns feature of DataFrames, as well as the iloc[] method).
Don't be afraid to use StackOverflow for help with this.
properties_T = properties.transpose()
properties_T = properties_T.reset_index()
properties_T.head()
# properties_T.iloc[[0]]
# type(properties_T.iloc[0])
properties_T.iloc[0,:]
properties_T.columns = list(properties_T.iloc[0,:])
# properties_T.columns = list(properties_T.iloc[[0]])
properties_T = properties_T.loc[1:,:]
properties_T.head()
2.3. Cleaning the data (part 2)
You might we have to rename a couple columns. How do you do this? The clue's pretty bold...
properties_T = properties_T.rename(columns={"Unnamed: 0": "borough", pd.NaT: "id"})
properties_T.head()
2.4.Transforming the data
Remember what Wes McKinney said about tidy data?
You might need to melt your DataFrame here.
properties_T_melt = properties_T.melt(id_vars=['borough','id'])
properties_T_melt.head()
Remember to make sure your column data types are all correct. Average prices, for example, should be floating point numbers...
properties_T_rename = properties_T_melt.rename(columns = {'variable':'date','value':'average_price'})
properties_T_rename.info()
# This function converts stringer into integer.
def str2int(s):
try:
return int(s)
except:
return np.nan
properties_T_rename['average_price'] = properties_T_rename['average_price'].apply(lambda x: str2int(x))
2.5. Cleaning the data (part 3)
Do we have an equal number of observations in the ID, Average Price, Month, and London Borough columns? Remember that there are only 32 London Boroughs. How many entries do you have in that column?
Check out the contents of the London Borough column, and if you find null values, get rid of them however you see fit.
set(properties_T_rename['borough'].unique())
properties_T_rename.isnull().sum()
properties_T_rename[properties_T_rename['id'].isnull()]
NaNFree_properties_T_rename = properties_T_rename.dropna()
NaNFree_properties_T_rename.isnull().sum()
2.6. Visualizing the data
To visualize the data, why not subset on a particular London Borough? Maybe do a line plot of Month against Average Price?
set(NaNFree_properties_T_rename['borough'].unique())
subBrough = ['Barking & Dagenham',
'Barnet',
'Bexley',
'Brent',
'Bromley',
'Camden',
# 'City of London',
'Croydon',
# 'EAST MIDLANDS',
# 'EAST OF ENGLAND',
'Ealing',
'Enfield',
'England',
'Greenwich',
'Hackney',
'Hammersmith & Fulham',
'Haringey',
'Harrow',
'Havering',
'Hillingdon',
'Hounslow',
# 'Inner London',
'Islington',
'Kensington & Chelsea',
'Kingston upon Thames',
'LONDON',
'Lambeth',
'Lewisham',
'Merton',
# 'NORTH EAST',
# 'NORTH WEST',
'Newham',
'Outer London',
'Redbridge',
'Richmond upon Thames',
# 'SOUTH EAST',
# 'SOUTH WEST',
'Southwark',
'Sutton',
'Tower Hamlets',
'WEST MIDLANDS',
'Waltham Forest',
'Wandsworth',
'Westminster',
'YORKS & THE HUMBER']
subset_NaNFree_properties_T_rename = NaNFree_properties_T_rename[NaNFree_properties_T_rename['borough'].isin(subBrough)]
# subset_NaNFree_properties_T_rename.head()
To limit the number of data points you have, you might want to extract the year from every month value your Month column.
To this end, you could apply a lambda function. Your logic could work as follows:
- look through the
Monthcolumn - extract the year from each individual value in that column
- store that corresponding year as separate column.
Whether you go ahead with this is up to you. Just so long as you answer our initial brief: which boroughs of London have seen the greatest house price increase, on average, over the past two decades?
subset_NaNFree_properties_T_rename['year']=subset_NaNFree_properties_T_rename['date'].apply(lambda x: x.year)
subset_NaNFree_properties_T_rename.head()
import cufflinks as cf
#We set the all charts as public
cf.set_config_file(sharing='public',theme='pearl',offline=False)
cf.go_offline()
subset_NaNFree_properties_T_rename.pivot_table(index='year', columns='borough', values='average_price',aggfunc=np.mean ).iplot(kind='scatter',xTitle='date',yTitle='borough',title='average price over years')
fig, ax = plt.subplots(figsize=(20, 15))
subset_NaNFree_properties_T_rename.pivot_table(index='year', columns='borough', values='average_price',aggfunc=np.mean ).plot(ax=ax)
ax.set_xlim(subset_NaNFree_properties_T_rename['year'].min(), subset_NaNFree_properties_T_rename['year'].max())
ax.set_ylim(0, subset_NaNFree_properties_T_rename['average_price'].max())
ax.ticklabel_format(style='plain')
plt.show()
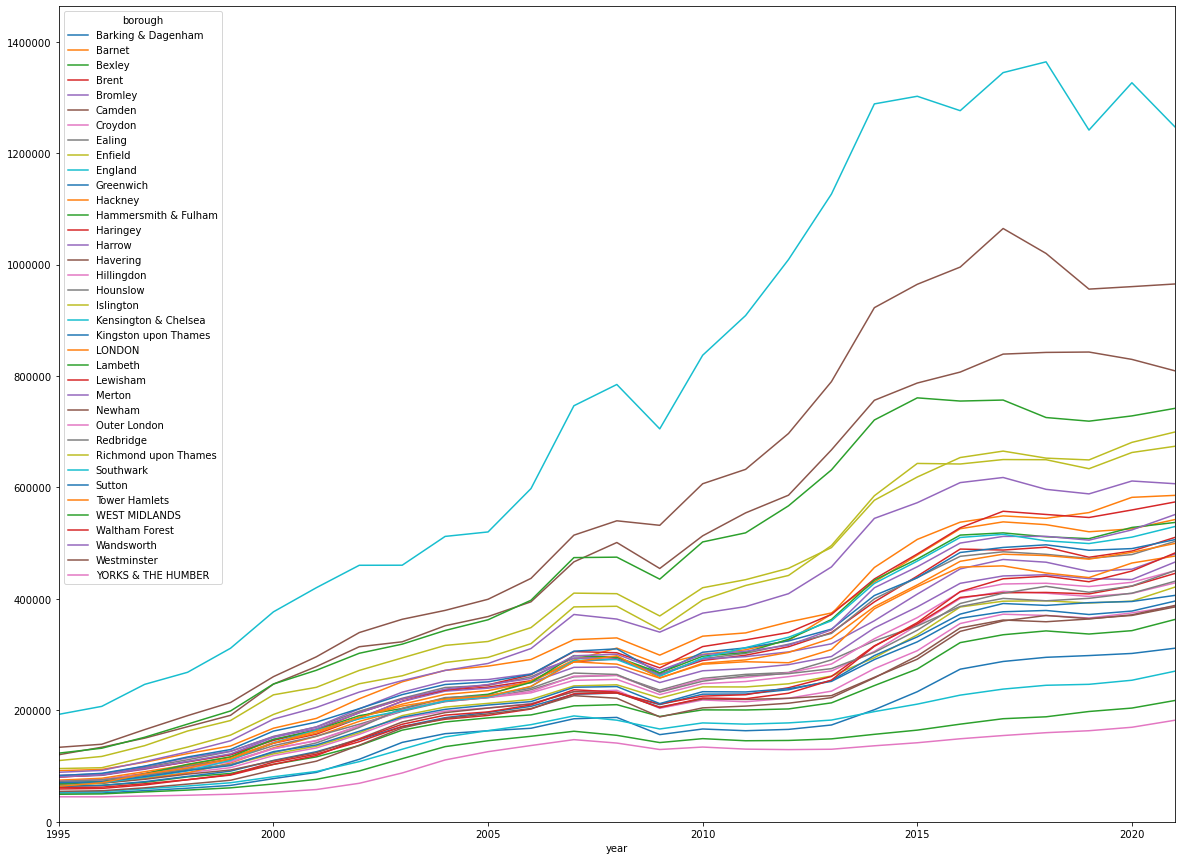
3. Modeling
Consider creating a function that will calculate a ratio of house prices, comparing the price of a house in 2018 to the price in 1998.
Consider calling this function create_price_ratio.
You'd want this function to:
- Take a filter of dfg, specifically where this filter constrains the London_Borough, as an argument. For example, one admissible argument should be: dfg[dfg['London_Borough']=='Camden'].
- Get the Average Price for that Borough, for the years 1998 and 2018.
- Calculate the ratio of the Average Price for 1998 divided by the Average Price for 2018.
- Return that ratio.
Once you've written this function, you ultimately want to use it to iterate through all the unique London_Boroughs and work out the ratio capturing the difference of house prices between 1998 and 2018.
Bear in mind: you don't have to write a function like this if you don't want to. If you can solve the brief otherwise, then great!
Hint: This section should test the skills you acquired in:
- Python Data Science Toolbox - Part One, all modules
dfg = subset_NaNFree_properties_T_rename.groupby(['borough','year']).mean()
dfg.reset_index().head()
ratio = (dfg.xs(2021,level='year')/dfg.xs(1998,level='year')).rename(columns={'average_price':'ratio'})
ratio.sort_values('ratio',ascending=False,inplace=True)
ratio.reset_index().head(5)
ratio.plot(kind='bar',y='ratio',figsize=(10,5),xlabel='Borough',ylabel='Price ratio(2021/1998)')
plt.show()
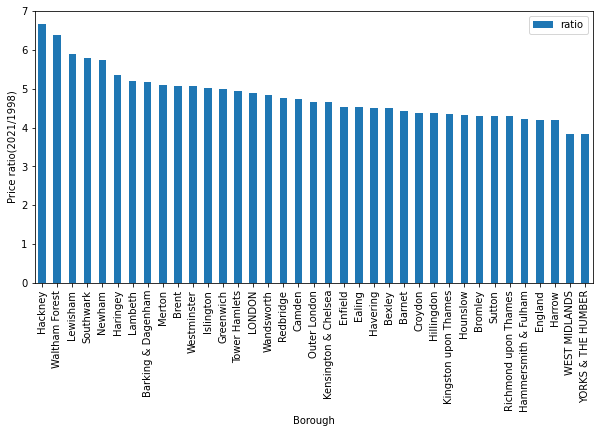
ratio.iplot(kind='bar',xTitle='Borough',yTitle='Price ratio(2018/1998)',title='Cufflinks - Bar Chart')
**if lambda function has to be used...¶
def create_price_ratio(df):
return (df[df['year']==2018]['average_price']).values/(df[df['year']==1998]['average_price']).values
df[df['year']==2018]['average_price'].values
reset_dfg = dfg.reset_index()
reset_dfg.head()
# reset_dfg.info()
ratio={}
for name in list(reset_dfg.borough.unique()):
ratio[name] = create_price_ratio(reset_dfg[reset_dfg['borough']==name])
ratio
pd_ratio = pd.DataFrame(ratio).T.rename(columns={0:'ratio'})
pd_ratio.sort_values('ratio').plot(kind='bar',xlabel='Borough',ylabel='Price ratio(2018/1998)',figsize=(15,5))
plt.show()
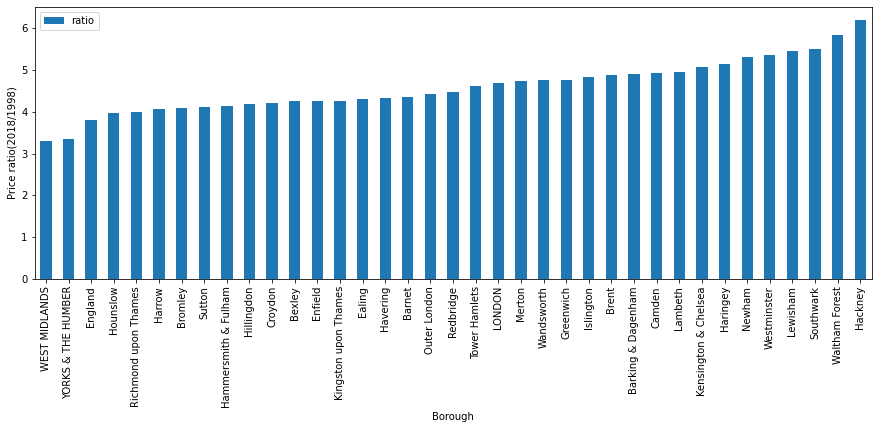
4. Conclusion¶
What can you conclude? Type out your conclusion below.
Look back at your notebook. Think about how you might summarize what you have done, and prepare a quick presentation on it to your mentor at your next meeting.
We hope you enjoyed this practical project. It should have consolidated your data hygiene and pandas skills by looking at a real-world problem involving just the kind of dataset you might encounter as a budding data scientist. Congratulations, and looking forward to seeing you at the next step in the course!
my answer¶
The graph shows the price ratio of houses in each borough, comparing the price of a house in 2018 to that in 1998.
Overall, all the rarios were positive. The median of the ratios is 4.5, the mean is 4.6, the IQR is 0.73, and the std is 0.63
The highest price ratio was about 6.2 in Hackney. This means that, the average price of a house in Hackney in 2018 was 6 times as expensive as the average price in 1998. In cnotrast, the lowest price ratio was 3.3 in WEST MIDLANDS. It can be prediced that the ratio of house price has strong correlation with borough.
When it comes to the changing rate of price, in the last year in the graph, some borough have positive trends, but the others have negatives.
In addition, as this graph indicates only average, there would be the other factors which affected the price or the changnig rate of price. These might be public transport, office, or facilities around the house.
gretest_price_2021 = dfg.xs(2021,level='year').reset_index().sort_values('average_price',ascending=False)
gretest_price_2021.head(5)
profit_ratio = ((dfg.xs(2021,level='year')/dfg.xs(1998,level='year'))**(1/26)-1).rename(columns={'average_price':'profit_ratio'})
profit_ratio.sort_values('profit_ratio',ascending=False,inplace=True)
profit_ratio.reset_index().head(30)
profit_ratio.reset_index().merge(profit_ratio.reset_index(),how='outer',on='borough')