Springboard Decision Tree Specialty Coffee Case Study - Tier 3¶
The Scenario¶
Imagine you've just finished the Springboard Data Science Career Track course, and have been hired by a rising popular specialty coffee company - RR Diner Coffee - as a data scientist. Congratulations!
RR Diner Coffee sells two types of thing:
- specialty coffee beans, in bulk (by the kilogram only)
- coffee equipment and merchandise (grinders, brewing equipment, mugs, books, t-shirts).
RR Diner Coffee has three stores, two in Europe and one in the USA. The flagshap store is in the USA, and everything is quality assessed there, before being shipped out. Customers further away from the USA flagship store have higher shipping charges.
You've been taken on at RR Diner Coffee because the company are turning towards using data science and machine learning to systematically make decisions about which coffee farmers they should strike deals with.
RR Diner Coffee typically buys coffee from farmers, processes it on site, brings it back to the USA, roasts it, packages it, markets it, and ships it (only in bulk, and after quality assurance) to customers internationally. These customers all own coffee shops in major cities like New York, Paris, London, Hong Kong, Tokyo, and Berlin.
Now, RR Diner Coffee has a decision about whether to strike a deal with a legendary coffee farm (known as the Hidden Farm) in rural China: there are rumours their coffee tastes of lychee and dark chocolate, while also being as sweet as apple juice.
It's a risky decision, as the deal will be expensive, and the coffee might not be bought by customers. The stakes are high: times are tough, stocks are low, farmers are reverting to old deals with the larger enterprises and the publicity of selling Hidden Farm coffee could save the RR Diner Coffee business.
Your first job, then, is to build a decision tree to predict how many units of the Hidden Farm Chinese coffee will be purchased by RR Diner Coffee's most loyal customers.
To this end, you and your team have conducted a survey of 710 of the most loyal RR Diner Coffee customers, collecting data on the customers':
- age
- gender
- salary
- whether they have bought at least one RR Diner Coffee product online
- their distance from the flagship store in the USA (standardized to a number between 0 and 11)
- how much they spent on RR Diner Coffee products on the week of the survey
- how much they spent on RR Diner Coffee products in the month preeding the survey
- the number of RR Diner coffee bean shipments each customer has ordered over the preceding year.
You also asked each customer participating in the survey whether they would buy the Hidden Farm coffee, and some (but not all) of the customers gave responses to that question.
You sit back and think: if more than 70% of the interviewed customers are likely to buy the Hidden Farm coffee, you will strike the deal with the local Hidden Farm farmers and sell the coffee. Otherwise, you won't strike the deal and the Hidden Farm coffee will remain in legends only. There's some doubt in your mind about whether 70% is a reasonable threshold, but it'll do for the moment.
To solve the problem, then, you will build a decision tree to implement a classification solution.
As ever, this notebook is tiered, meaning you can elect that tier that is right for your confidence and skill level. There are 3 tiers, with tier 1 being the easiest and tier 3 being the hardest. This is tier 3, so it will be challenging.
1. Sourcing and loading
- Import packages
- Load data
- Explore the data
2. Cleaning, transforming and visualizing
- Cleaning the data
- Train/test split
3. Modelling
- Model 1: Entropy model - no max_depth
- Model 2: Gini impurity model - no max_depth
- Model 3: Entropy model - max depth 3
- Model 4: Gini impurity model - max depth 3
4. Evaluating and concluding
- How many customers will buy Hidden Farm coffee?
- Decision
5. Random Forest
- Import necessary modules
- Model
- Revise conclusion
0. Overview¶
This notebook uses decision trees to determine whether the factors of salary, gender, age, how much money the customer spent last week and during the preceding month on RR Diner Coffee products, how many kilogram coffee bags the customer bought over the last year, whether they have bought at least one RR Diner Coffee product online, and their distance from the flagship store in the USA, could predict whether customers would purchase the Hidden Farm coffee if a deal with its farmers were struck.
import pandas as pd
import numpy as np
from sklearn import tree, metrics
from sklearn.model_selection import train_test_split
import seaborn as sns
import matplotlib.pyplot as plt
from io import StringIO
from IPython.display import Image
import pydotplus
1b. Load data¶
# Read in the data to a variable called coffeeData
coffeeData = pd.read_csv('data/RRDinerCoffeeData.csv')
1c. Explore the data¶
As we've seen, exploration entails doing things like checking out the initial appearance of the data with head(), the dimensions of our data with .shape, the data types of the variables with .info(), the number of non-null values, how much memory is being used to store the data, and finally the major summary statistcs capturing central tendancy, dispersion and the null-excluding shape of the dataset's distribution.
How much of this can you do yourself by this point in the course? Have a real go.
# Call head() on your data
coffeeData.head()
# Call .shape on your data
coffeeData.shape
# Call info() on your data
coffeeData.info()
# Call describe() on your data to get the relevant summary statistics for your data
coffeeData.describe(include='all').T
Some datasets don't require any cleaning, but almost all do. This one does. We need to replace '1.0' and '0.0' in the 'Decision' column by 'YES' and 'NO' respectively, clean up the values of the 'gender' column, and change the column names to words which maximize meaning and clarity.
First, let's change the name of spent_week, spent_month, and SlrAY to spent_last_week and spent_last_month and salary respectively.
# Check out the names of our data's columns
coffeeData.columns
# Make the relevant name changes to spent_week and spent_per_week.
coffeeData.rename(columns={'spent_week': 'spent_per_week'},inplace=True)
# Check out the column names
coffeeData.columns
# Let's have a closer look at the gender column. Its values need cleaning.
coffeeData['Gender'].value_counts()
# See the gender column's unique values
coffeeData['Gender'].unique()
We can see a bunch of inconsistency here.
Use replace() to make the values of the gender column just Female and Male.
# Replace all alternate values for the Female entry with 'Female'
coffeeData['Gender'] = coffeeData['Gender'].str.strip()
coffeeData['Gender'] = coffeeData['Gender'].replace(['male','M','MALE'],'Male')
coffeeData['Gender'] = coffeeData['Gender'].replace(['female','f','F','FEMALE'],'Female')
coffeeData['Gender'].value_counts()
# Check out the unique values for the 'gender' column
coffeeData['Gender'].unique()
# Replace all alternate values with "Male"
# done above
# Let's check the unique values of the column "gender"
# done above
# Check out the unique values of the column 'Decision'
coffeeData['Decision'].unique()
We now want to replace 1.0 and 0.0 in the Decision column by YES and NO respectively.
# Replace 1.0 and 0.0 by 'Yes' and 'No'
coffeeData['Decision'] = coffeeData['Decision'].replace(1.0,'YES')
coffeeData['Decision'] = coffeeData['Decision'].replace(0,'NO')
# Check that our replacing those values with 'YES' and 'NO' worked, with unique()
coffeeData['Decision'].unique()
coffeeData['Decision'].isna().sum()
2b. Train/test split¶
To execute the train/test split properly, we need to do five things:
- Drop all rows with a null value in the
Decisioncolumn, and save the result as NOPrediction: a dataset that will contain all known values for the decision - Visualize the data using scatter and boxplots of several variables in the y-axis and the decision on the x-axis
- Get the subset of coffeeData with null values in the
Decisioncolumn, and save that subset as Prediction - Divide the NOPrediction subset into X and y, and then further divide those subsets into train and test subsets for X and y respectively
- Create dummy variables to deal with categorical inputs
1. Drop all null values within the Decision column, and save the result as NoPrediction¶
# NoPrediction will contain all known values for the decision
# Call dropna() on coffeeData, and store the result in a variable NOPrediction
# Call describe() on the Decision column of NoPrediction after calling dropna() on coffeeData
NOPrediction = coffeeData.dropna(subset=['Decision'])
NOPrediction['Decision'].dropna().describe(include='all')
2. Visualize the data using scatter and boxplots of several variables in the y-axis and the decision on the x-axis¶
# Exploring our new NOPrediction dataset
# Make a boxplot on NOPrediction where the x axis is Decision, and the y axis is spent_last_week
import cufflinks as cf
cf.go_offline()
NOPrediction.columns
NOPrediction.head()
# NOPrediction.groupby('Decision').sum()['spent_per_week']
NOPrediction.pivot(columns='Decision', values='spent_per_week').iplot(kind='box')
Can you admissibly conclude anything from this boxplot? Write your answer here:
# Make a scatterplot on NOPrediction, where x is distance, y is spent_last_month and hue is Decision
NOPrediction.iplot(kind='scatter',x='Distance',y='spent_month',mode='markers',
size=10,
categories="Decision",
xTitle='Distance',
yTitle='spent_month',)
Can you admissibly conclude anything from this scatterplot? Remember: we are trying to build a tree to classify unseen examples. Write your answer here:
Two things can be observed.
Firstly, the longer Distance, the more ratio of Yes Decision comapred to No Decision. Secondly, the shorter Distance, the more pay in month.
Both observaiton is generally intuitive and it makes sense.
3. Get the subset of coffeeData with null values in the Decision column, and save that subset as Prediction¶
# Get just those rows whose value for the Decision column is null
Prediction = coffeeData[coffeeData['Decision'].isnull()]
Prediction.head()
# Call describe() on Prediction
Prediction.describe().T
4. Divide the NOPrediction subset into X and y¶
# Check the names of the columns of NOPrediction
NOPrediction.columns
# Let's do our feature selection.
# Make a variable called 'features', and a list containing the strings of every column except "Decision"
features = ['Age', 'Gender', 'num_coffeeBags_per_year', 'spent_per_week',
'spent_month', 'SlrAY', 'Distance', 'Online']
# Make an explanatory variable called X, and assign it: NoPrediction[features]
X = NOPrediction[features]
# Make a dependent variable called y, and assign it: NoPrediction.Decision
y = NOPrediction.Decision
5. Create dummy variables to deal with categorical inputs¶
One-hot encoding replaces each unique value of a given column with a new column, and puts a 1 in the new column for a given row just if its initial value for the original column matches the new column. Check out this resource if you haven't seen one-hot-encoding before.
Note: We will do this before we do our train/test split as to do it after could mean that some categories only end up in the train or test split of our data by chance and this would then lead to different shapes of data for our X_train and X_test which could/would cause downstream issues when fitting or predicting using a trained model.
# One-hot encode all features in X.
X = pd.get_dummies(X,drop_first=True,prefix='dummy')
X
6. Further divide those subsets into train and test subsets for X and y respectively: X_train, X_test, y_train, y_test¶
# Call train_test_split on X, y. Make the test_size = 0.25, and random_state = 246
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.25, random_state=246)
3. Modelling¶
It's useful to look at the scikit-learn documentation on decision trees https://scikit-learn.org/stable/modules/tree.html before launching into applying them. If you haven't seen them before, take a look at that link, in particular the section 1.10.5.
Model 1: Entropy model - no max_depth¶
We'll give you a little more guidance here, as the Python is hard to deduce, and scikitlearn takes some getting used to.
Theoretically, let's remind ourselves of what's going on with a decision tree implementing an entropy model.
Ross Quinlan's ID3 Algorithm was one of the first, and one of the most basic, to use entropy as a metric.
Entropy is a measure of how uncertain we are about which category the data-points fall into at a given point in the tree. The Information gain of a specific feature with a threshold (such as 'spent_last_month <= 138.0') is the difference in entropy that exists before and after splitting on that feature; i.e., the information we gain about the categories of the data-points by splitting on that feature and that threshold.
Naturally, we want to minimize entropy and maximize information gain. Quinlan's ID3 algorithm is designed to output a tree such that the features at each node, starting from the root, and going all the way down to the leaves, have maximial information gain. We want a tree whose leaves have elements that are homogeneous, that is, all of the same category.
The first model will be the hardest. Persevere and you'll reap the rewards: you can use almost exactly the same code for the other models.
# Declare a variable called entr_model and use tree.DecisionTreeClassifier.
entr_model = tree.DecisionTreeClassifier(criterion = 'entropy',random_state = 1234)
# Call fit() on entr_model
entr_model.fit(X_train,y_train)
# Call predict() on entr_model with X_test passed to it, and assign the result to a variable y_pred
y_pred = entr_model.predict(X_test)
# Call Series on our y_pred variable with the following: pd.Series(y_pred)
y_pred = pd.Series(y_pred)
# Check out entr_model
entr_model
entr_model.classes_
# Now we want to visualize the tree
dot_data = StringIO()
# We can do so with export_graphviz
tree.export_graphviz(entr_model, out_file=dot_data,
filled=True, rounded=True,special_characters=True,
feature_names=X_train.columns,
class_names = entr_model.classes_
)
# Alternatively for class_names use entr_model.classes_
graph = pydotplus.graph_from_dot_data(dot_data.getvalue())
Image(graph.create_png())
Model 1: Entropy model - no max_depth: Interpretation and evaluation¶
# Run this block for model evaluation metrics
print("Model Entropy - no max depth")
# print("Accuracy:", metrics.accuracy_score(y_test,y_pred))
# print("Balanced accuracy:", metrics.balanced_accuracy_score(y_test,y_pred))
# print('Precision score for "Yes"' , metrics.precision_score(y_test,y_pred, pos_label = "YES"))
# print('Precision score for "No"' , metrics.precision_score(y_test,y_pred, pos_label = "NO"))
# print('Recall score for "Yes"' , metrics.recall_score(y_test,y_pred, pos_label = "YES"))
# print('Recall score for "No"' , metrics.recall_score(y_test,y_pred, pos_label = "NO"))
from sklearn.metrics import classification_report,confusion_matrix
print(classification_report(y_test,y_pred))
from mlxtend.plotting import plot_confusion_matrix
fig, ax = plot_confusion_matrix(conf_mat=confusion_matrix(y_test,y_pred), figsize=(3, 3))
plt.show()
What can you infer from these results? Write your conclusions here:
It's almost perfect. Tree structure looks complex probably due to the no limit of depth.
Model 2: Gini impurity model - no max_depth¶
Gini impurity, like entropy, is a measure of how well a given feature (and threshold) splits the data into categories.
Their equations are similar, but Gini impurity doesn't require logorathmic functions, which can be computationally expensive.
# Make a variable called gini_model, and assign it exactly what you assigned entr_model with above, but with the
# criterion changed to 'gini'
gini_model = tree.DecisionTreeClassifier(criterion = 'gini',random_state = 1234)
# Call fit() on the gini_model as you did with the entr_model
gini_model.fit(X_train,y_train)
# Call predict() on the gini_model as you did with the entr_model
y_pred = gini_model.predict(X_test)
# Turn y_pred into a series, as before
y_pred = pd.Series(y_pred)
# Check out gini_model
gini_model
# As before, but make the model name gini_model
dot_data = StringIO()
tree.export_graphviz(gini_model, out_file=dot_data,
filled=True, rounded=True,special_characters=True,
feature_names=X_train.columns,
class_names = gini_model.classes_
)
# Alternatively for class_names use gini_model.classes_
graph = pydotplus.graph_from_dot_data(dot_data.getvalue())
Image(graph.create_png())
# Run this block for model evaluation
print("Model Gini impurity model")
# print("Accuracy:", metrics.accuracy_score(y_test,y_pred))
# print("Balanced accuracy:", metrics.balanced_accuracy_score(y_test,y_pred))
# print('Precision score' , metrics.precision_score(y_test,y_pred, pos_label = "YES"))
# print('Recall score' , metrics.recall_score(y_test,y_pred, pos_label = "NO"))
from sklearn.metrics import classification_report,confusion_matrix
print(classification_report(y_test,y_pred))
from mlxtend.plotting import plot_confusion_matrix
fig, ax = plot_confusion_matrix(conf_mat=confusion_matrix(y_test,y_pred), figsize=(3, 3))
plt.show()
How do the results here compare to the previous model? Write your judgements here:
It's less accurate than Model Entropy with no max depth, but it still looks a good result in this example. Tree structure looks unbalanced (left side looks heavier) probably due to this Gini impurity model.
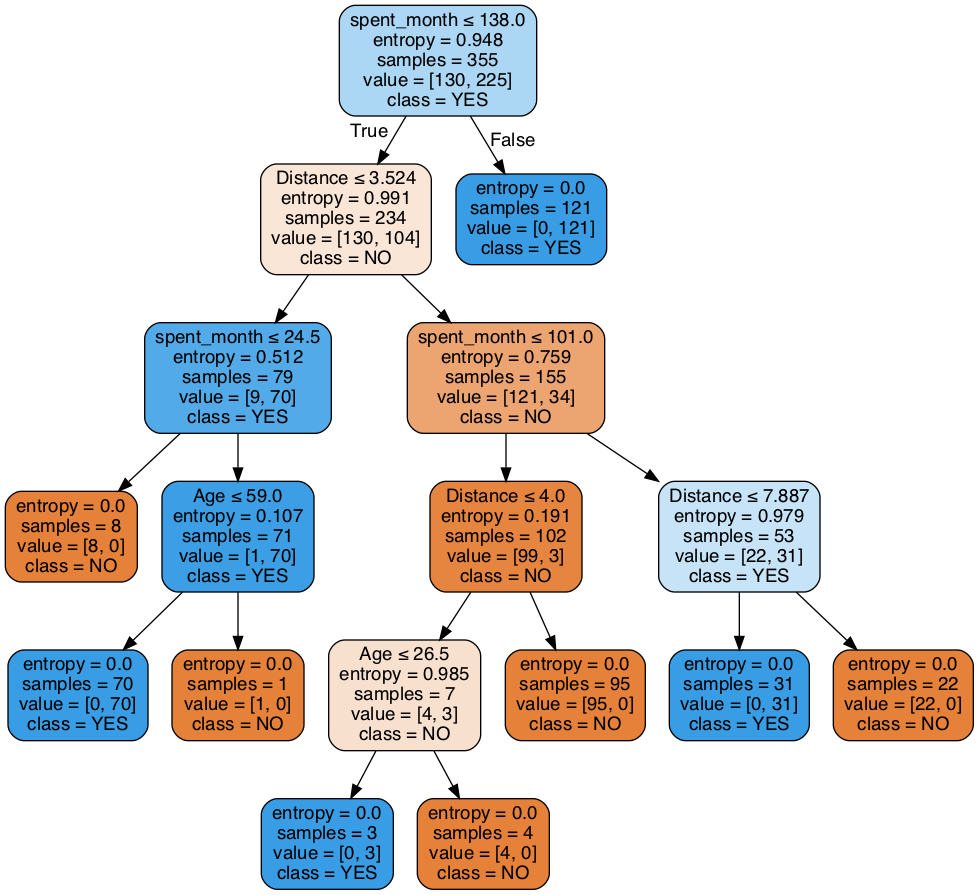
Model 3: Entropy model - max depth 3¶
We're going to try to limit the depth of our decision tree, using entropy first.
As you know, we need to strike a balance with tree depth.
Insufficiently deep, and we're not giving the tree the opportunity to spot the right patterns in the training data.
Excessively deep, and we're probably going to make a tree that overfits to the training data, at the cost of very high error on the (hitherto unseen) test data.
Sophisticated data scientists use methods like random search with cross-validation to systematically find a good depth for their tree. We'll start with picking 3, and see how that goes.
# Made a model as before, but call it entr_model2, and make the max_depth parameter equal to 3.
# Execute the fitting, predicting, and Series operations as before
entr_model2 = tree.DecisionTreeClassifier(criterion="entropy", max_depth = 3, random_state = 1234)
entr_model2.fit(X_train,y_train)
y_pred = entr_model2.predict(X_test)
y_pred = pd.Series(y_pred)
entr_model2
# As before, we need to visualize the tree to grasp its nature
dot_data = StringIO()
tree.export_graphviz(entr_model2, out_file=dot_data,
filled=True, rounded=True,special_characters=True,
feature_names=X_train.columns,
class_names = entr_model2.classes_
)
# Alternatively for class_names use entr_model2.classes_
graph = pydotplus.graph_from_dot_data(dot_data.getvalue())
Image(graph.create_png())
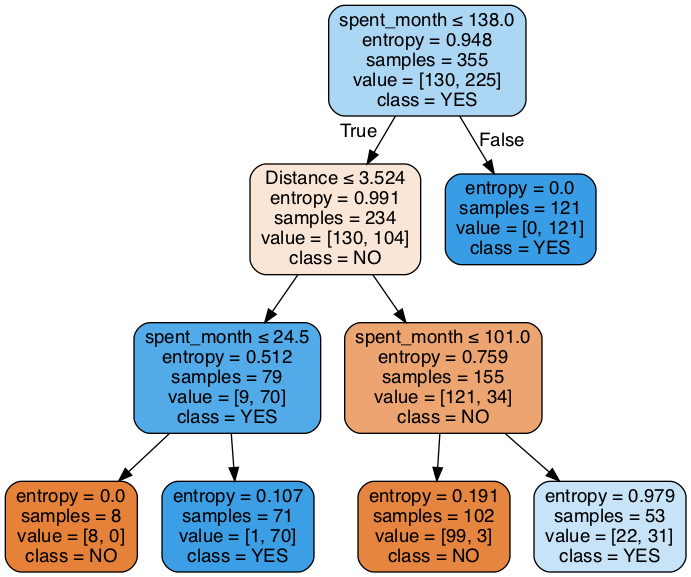
# Run this block for model evaluation
print("Model Entropy model max depth 3")
# print("Accuracy:", metrics.accuracy_score(y_test,y_pred))
# print("Balanced accuracy:", metrics.balanced_accuracy_score(y_test,y_pred))
# print('Precision score for "Yes"' , metrics.precision_score(y_test,y_pred, pos_label = "YES"))
# print('Recall score for "No"' , metrics.recall_score(y_test,y_pred, pos_label = "NO"))
from sklearn.metrics import classification_report,confusion_matrix
print(classification_report(y_test,y_pred))
from mlxtend.plotting import plot_confusion_matrix
fig, ax = plot_confusion_matrix(conf_mat=confusion_matrix(y_test,y_pred), figsize=(3, 3))
plt.show()
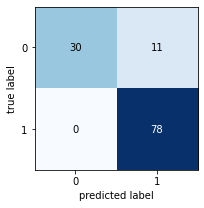
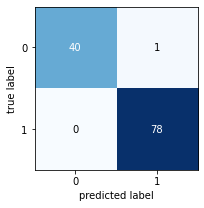
So our accuracy decreased, but is this certainly an inferior tree to the max depth original tree we did with Model 1? Write your conclusions here:
The result is worse than the frist one without max depth, but tree structure is very simple, so calcualtion must have been far more efficient than one without maxt depth.
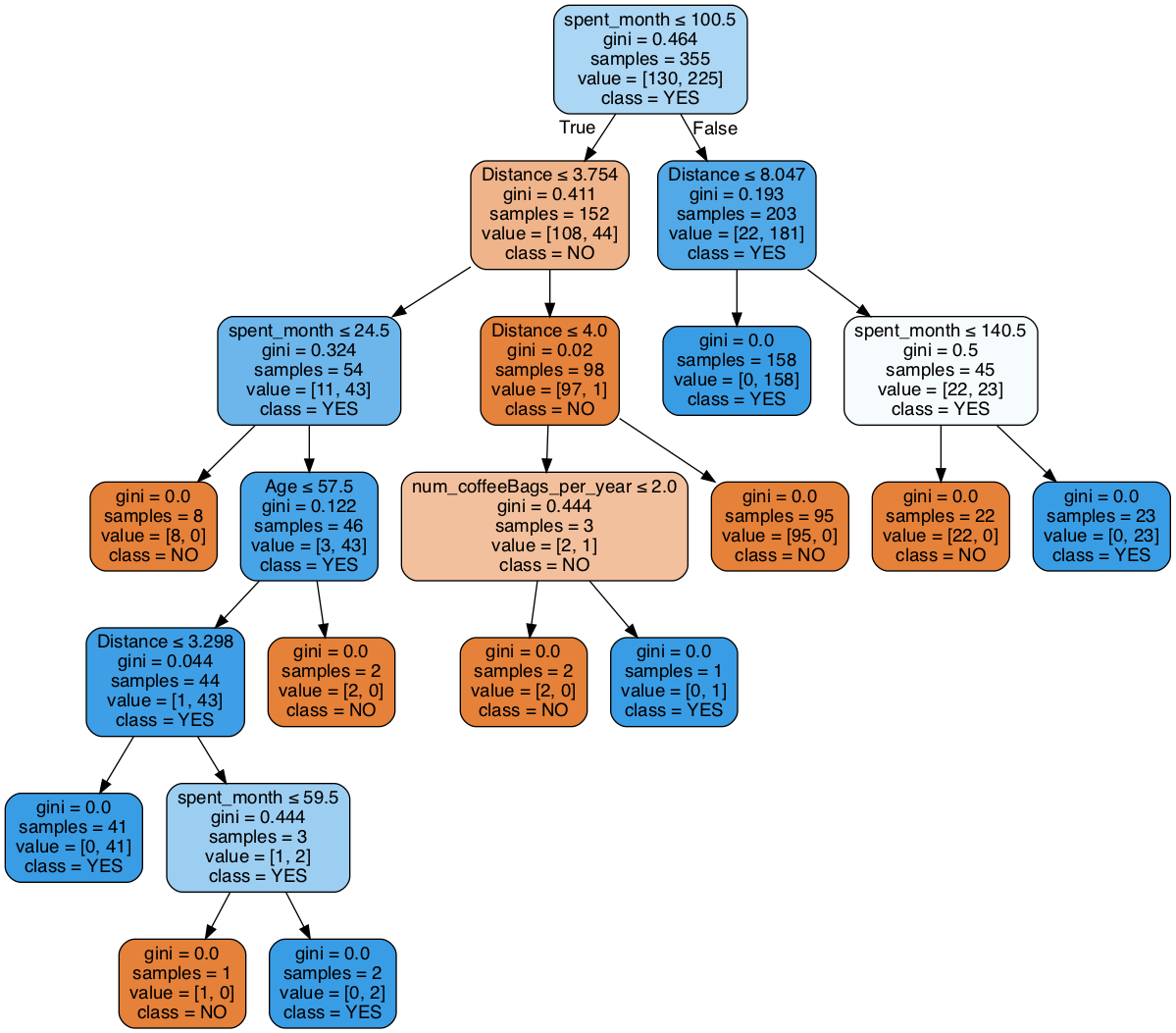
Model 4: Gini impurity model - max depth 3¶
We're now going to try the same with the Gini impurity model.
# As before, make a variable, but call it gini_model2, and ensure the max_depth parameter is set to 3
gini_model2=tree.DecisionTreeClassifier(criterion='gini', random_state = 1234, max_depth = 3 )
# Do the fit, predict, and series transformations as before.
gini_model2.fit(X_train,y_train)
y_pred=gini_model2.predict(X_test)
y_pred = pd.Series(y_pred)
gini_model2
dot_data = StringIO()
tree.export_graphviz(gini_model2, out_file=dot_data,
filled=True, rounded=True,special_characters=True,
feature_names=X_train.columns,
class_names = gini_model2.classes_
)
# Alternatively for class_names use gini_model2.classes_
graph = pydotplus.graph_from_dot_data(dot_data.getvalue())
Image(graph.create_png())
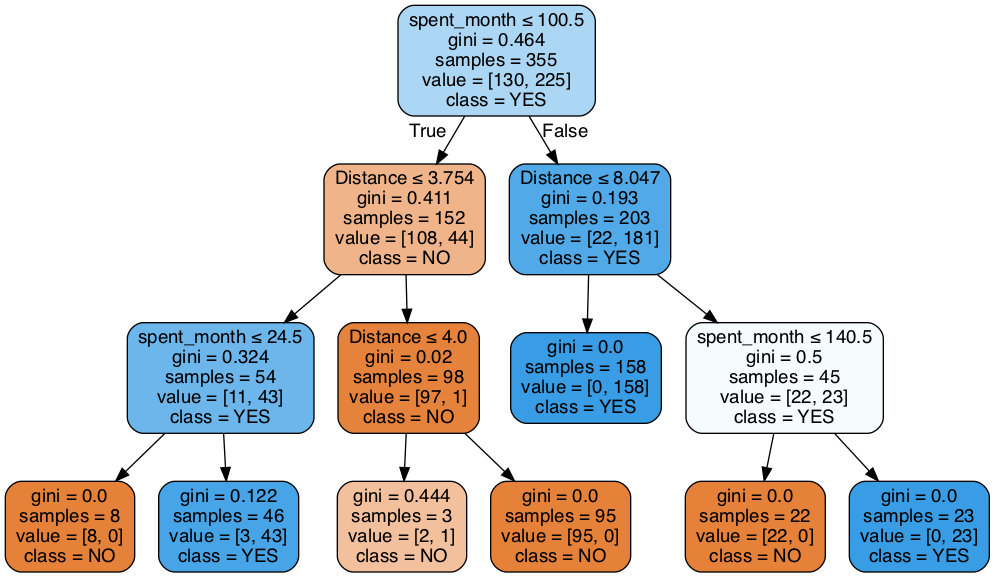
print("Gini impurity model - max depth 3")
# print("Accuracy:", metrics.accuracy_score(y_test,y_pred))
# print("Balanced accuracy:", metrics.balanced_accuracy_score(y_test,y_pred))
# print('Precision score' , metrics.precision_score(y_test,y_pred, pos_label = "YES"))
# print('Recall score' , metrics.recall_score(y_test,y_pred, pos_label = "NO"))
from sklearn.metrics import classification_report,confusion_matrix
print(classification_report(y_test,y_pred))
from mlxtend.plotting import plot_confusion_matrix
fig, ax = plot_confusion_matrix(conf_mat=confusion_matrix(y_test,y_pred), figsize=(3, 3))
plt.show()
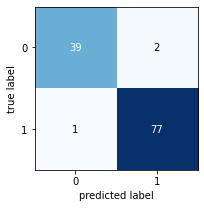
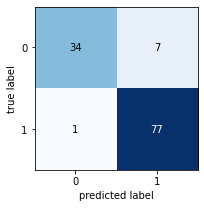
Now this is an elegant tree. Its accuracy might not be the highest, but it's still the best model we've produced so far. Why is that? Write your answer here:
The result is slightly worse. But, although tree structure is much simpler in the same degree with Entropy model, decrease in reault has little difference. Furthermore, the calcualtion must also have been far more efficient than one without max depth.
# Call value_counts() on the 'Decision' column of the original coffeeData
coffeeData['Decision'].value_counts()
Let's now determine the number of people that, according to the model, will be willing to buy the Hidden Farm coffee.
- First we subset the Prediction dataset into
new_Xconsidering all the variables exceptDecision - Use that dataset to predict a new variable called
potential_buyers
coffeeData.columns.isin(features)
# Feature selection
# Make a variable called feature_cols, and assign it a list containing all the column names except 'Decision'
feature_cols = features
# Make a variable called new_X, and assign it the subset of Prediction, containing just the feature_cols
new_X = Prediction[features]
# Call get_dummies() on the Pandas object pd, with new_X plugged in, to one-hot encode all features in the training set
new_X = pd.get_dummies(new_X,drop_first=True,prefix='dummy')
# Make a variable called potential_buyers, and assign it the result of calling predict() on a model of your choice;
# don't forget to pass new_X to predict()
potential_buyers = gini_model2.predict(new_X)
# Let's get the numbers of YES's and NO's in the potential buyers
# Call unique() on np, and pass potential_buyers and return_counts=True
np.unique(potential_buyers,return_counts=True)
The total number of potential buyers is 303 + 183 = 486
# Print the total number of surveyed people
total = len(y)+len(potential_buyers)
# Let's calculate the proportion of buyers
(sum(y=='YES')+sum(potential_buyers=='YES'))/total
# Print the percentage of people who want to buy the Hidden Farm coffee, by our model
sum(potential_buyers=='YES'),len(potential_buyers),str(sum(potential_buyers=='YES')/len(potential_buyers)*100)+'%'
4b. Decision¶
Remember how you thought at the start: if more than 70% of the interviewed customers are likely to buy the Hidden Farm coffee, you will strike the deal with the local Hidden Farm farmers and sell the coffee. Otherwise, you won't strike the deal and the Hidden Farm coffee will remain in legends only. Well now's crunch time. Are you going to go ahead with that idea? If so, you won't be striking the deal with the Chinese farmers.
They're called decision trees, aren't they? So where's the decision? What should you do? (Cue existential cat emoji).
Ultimately, though, we can't write an algorithm to actually make the business decision for us. This is because such decisions depend on our values, what risks we are willing to take, the stakes of our decisions, and how important it us for us to know that we will succeed. What are you going to do with the models you've made? Are you going to risk everything, strike the deal with the Hidden Farm farmers, and sell the coffee?
The philosopher of language Jason Stanley once wrote that the number of doubts our evidence has to rule out in order for us to know a given proposition depends on our stakes: the higher our stakes, the more doubts our evidence has to rule out, and therefore the harder it is for us to know things. We can end up paralyzed in predicaments; sometimes, we can act to better our situation only if we already know certain things, which we can only if our stakes were lower and we'd already bettered our situation.
Data science and machine learning can't solve such problems. But what it can do is help us make great use of our data to help inform our decisions.
5. Random Forest¶
You might have noticed an important fact about decision trees. Each time we run a given decision tree algorithm to make a prediction (such as whether customers will buy the Hidden Farm coffee) we will actually get a slightly different result. This might seem weird, but it has a simple explanation: machine learning algorithms are by definition stochastic, in that their output is at least partly determined by randomness.
To account for this variability and ensure that we get the most accurate prediction, we might want to actually make lots of decision trees, and get a value that captures the centre or average of the outputs of those trees. Luckily, there's a method for this, known as the Random Forest.
Essentially, Random Forest involves making lots of trees with similar properties, and then performing summary statistics on the outputs of those trees to reach that central value. Random forests are hugely powerful classifers, and they can improve predictive accuracy and control over-fitting.
Why not try to inform your decision with random forest? You'll need to make use of the RandomForestClassifier function within the sklearn.ensemble module, found here.
5a. Import necessary modules¶
from sklearn.ensemble import RandomForestClassifier
from sklearn.datasets import make_classification
5b. Model¶
You'll use your X_train and y_train variables just as before.
You'll then need to make a variable (call it firstRFModel) to store your new Random Forest model. You'll assign this variable the result of calling RandomForestClassifier().
Then, just as before, you'll call fit() on that firstRFModel variable, and plug in X_train and y_train.
Finally, you should make a variable called y_pred, and assign it the result of calling the predict() method on your new firstRFModel, with the X_test data passed to it.
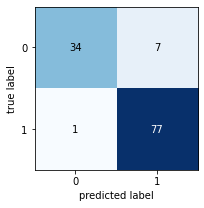
# Plug in appropriate max_depth and random_state parameters
firstRFModel = RandomForestClassifier(max_depth=3,random_state=True)
# Model and fit
firstRFModel.fit(X_train,y_train)
y_pred = firstRFModel.predict(X_test)
y_pred = pd.Series(y_pred)
firstRFModel
print("RandomForestClassifier, max_depth=3")
# print("Accuracy:", metrics.accuracy_score(y_test,y_pred))
# print("Balanced accuracy:", metrics.balanced_accuracy_score(y_test,y_pred))
# print('Precision score' , metrics.precision_score(y_test,y_pred, pos_label = "YES"))
# print('Recall score' , metrics.recall_score(y_test,y_pred, pos_label = "NO"))
from sklearn.metrics import classification_report,confusion_matrix
print(classification_report(y_test,y_pred))
from mlxtend.plotting import plot_confusion_matrix
fig, ax = plot_confusion_matrix(conf_mat=confusion_matrix(y_test,y_pred), figsize=(3, 3))
plt.show()
# This may not the best way to view each estimator as it is small
fn=X_train.columns
cn=["NO", "YES"]
fig, axes = plt.subplots(nrows = 1,ncols = 5,figsize = (10,2), dpi=900)
for index in range(0, 5):
tree.plot_tree(firstRFModel.estimators_[index],
feature_names = fn,
class_names=cn,
filled = True,
ax = axes[index]);
axes[index].set_title('Estimator: ' + str(index), fontsize = 11)
fig.savefig('rf_5trees.png')
# ref:https://stackoverflow.com/questions/40155128/plot-trees-for-a-random-forest-in-python-with-scikit-learn
# Make a prediction
potential_buyers = firstRFModel.predict(new_X)
# Let's get the numbers of YES's and NO's in the potential buyers
# Call unique() on np, and pass potential_buyers and return_counts=True
np.unique(potential_buyers,return_counts=True)
# Print the percentage of people who want to buy the Hidden Farm coffee, by our model
sum(potential_buyers=='YES'),len(potential_buyers),str(sum(potential_buyers=='YES')/len(potential_buyers)*100)+'%'
5c. Revise conclusion¶
Has your conclusion changed? Or is the result of executing random forest the same as your best model reached by a single decision tree?
Referring to the tables below, among the models with max-depth == 3, this random forest model(RFM) prediction has slightly worse result than Gini model, although it's better than Entropy model.
Theoretically speaking, RFM should perform in less biased way. I predict one of the reasons why we got worse result in RFM is that decision tree could more fit (overfit) to the features.
Model Entropy model max depth 3¶
precision recall f1-score support
NO 1.00 0.73 0.85 41
YES 0.88 1.00 0.93 78
accuracy 0.91 119
macro avg 0.94 0.87 0.89 119 weighted avg 0.92 0.91 0.90 119
Gini impurity model - max depth 3¶
precision recall f1-score support
NO 0.97 0.95 0.96 41
YES 0.97 0.99 0.98 78
accuracy 0.97 119
macro avg 0.97 0.97 0.97 119 weighted avg 0.97 0.97 0.97 119
RandomForestClassifier, max_depth=3¶
precision recall f1-score support
NO 0.97 0.83 0.89 41
YES 0.92 0.99 0.95 78
accuracy 0.93 119
macro avg 0.94 0.91 0.92 119 weighted avg 0.94 0.93 0.93 119